一、解决过拟合问题
所谓过拟合(over-fitting)其实就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。造成过拟合的本质原因是模型学习的太过精密,导致连训练集中的样本噪声也一丝不差的训练进入了模型。
所谓欠拟合(under-fitting),与过拟合恰好相反,模型学习的太过粗糙,连训练集中的样本数据特征关系(数据分布)都没有学出来。
解决过拟合的方法主要有以下几种:
(1) 数据层面:- 数据增广(Data Augmentation), 获取更多数据。
- 特征工程,筛选组合得到更高质量特征。
- 选择较为简单的模型
- 集成学习,Bagging策略组合模型降低模型方差。
- 加入正则项,如L1、L2正则项,以及树模型的剪枝策略,XGBoost中的正则项惩罚(叶子节点值+叶子节点个数)。
- 早停(Early stopping),在模型的训练精度已经到达一定的需求时停止训练,以防止模型学习过多的样本噪声。
- 加入噪声,给定训练样本集更多的样本噪声,使得模型不易完全拟合这些噪声,从而只在大程度上的训练学习我们想要的数据特征关系。
- dropout,在深度学习中,我们经常会使用dropout的方法来防止过拟合,dropout实际上借鉴来bagging的思想。
- BN(Batch Normalization),BN每一次训练中所组成的Mini-Batch类似于Bagging策略,不同的Mini-Batch训练出来的BN参数也不同。
- 权重衰减(Weight Deacy),Weight Deacy实际上是使得模型在训练后期,权重的变化变得很慢很慢,从而使得模型不至于在迭代后期转而去学习更多的样本噪声。常用的权重衰减方法有滑动平均(Moving Average)。
二、正则化方法:防止过拟合,提高模型泛化能力
- L1正则化是指权值向量$w$中各个元素的绝对值之和,通常表示为$||w||_1$。
- L2正则化是指权值向量$w$中各个元素的平方和然后再求平方根,通常表示为$||w||_2$
2.1 为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于0的)
我们考虑如下带L1正则化的损失函数:
\[C =C_0+\alpha \sum_w|w|\]其中$C_0$是原始的损失函数,加号后面的一项是L1正则化项,$\alpha$是正则化系数。注意到L1正则化是权值的绝对值之和,$C$是带有绝对值符号的函数,因此$C$是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数$C_0$后添加L1正则化项时,相当于对$C_0$做了一个约束。此时我们的任务变成在正则化约束下求出$C_0$取最小值的解。
考虑二维的情况,即只有两个权值$w^1,w^2$,此时 \(L_1 = |w^1|+|w^2|\) 对于梯度下降法,求解$C_0$的过程可以画出等值线,同时L1正则化的函数也可以在$w^1w^2$的二维平面上画出来。如下图:
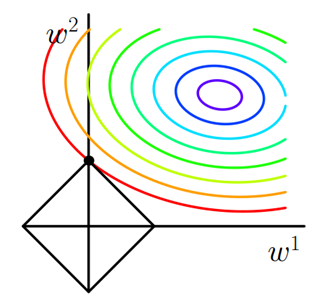
图中等值线是$C_0$的等值线,黑色方形是L1正则函数的图形。
在图中,当$C_0$等值线与L1图形首次相交的地方就是最优解(可以参考:带约束的最优化问题)。上图中$C_0$与L1正则在L1正则的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是$(w^1,w^2)=(0,w)$。可以直观想象,因为L1正则化函数有很多『突出的角』(二维情况下四个,多维情况下更多),$C_0$与这些角接触的机率会远大于与其它部位接触的机率(这是很直觉的想象,突出的角比直线的边离等值线更近写),而在这些角上,会有很多权值等于0(因为角就在坐标轴上),这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数$\alpha$,可以控制L1正则图形的大小。正则项整体大小不变时,$\alpha$越小(惩罚越弱),相应的$w$就越大($w$越不受限),图形就越大(越容易过拟合);$\alpha$越大,L1正则图形就越小,可以小到黑色方框只超出原点范围一点点,这时最优点的值$(w^1,w^2)=(0,w)$中的$w$可以取到很小的值。但会导致损失函数最优值变大,导致欠拟合。
模型参数稀疏的优点:
(1) 特征选择(Feature Selection)稀疏规则化能实现特征的自动选择。一般来说,$x_i$的大部分元素(也就是特征)都是和最终的输出$y_i$没有关系或者不提供任何信息的,在最小化目标函数的时候考虑这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的信息反而会被考虑,从而干扰了对正确$y_i$的预测。稀疏规则化算子会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。简单来讲,越好的特征包含的数据分布信息越多,差的特征也包含一定的数据分布信息,但同时还会包含大量的噪声,特征选择旨在于选择出好的特征去学习,而不是为了一点点的模型训练提升去引入学习更多的噪声。
(2) 可解释性(Interpretability)另一个青睐于稀疏的理由是,模型更容易解释。最后的模型输出是关于一堆特征的加权组合,如果特征有几千个,解释起来就很困难。但如果通过特征选择过滤出来5个特征,然后经过训练发现效果也不错,那这样的模型在解释起来就容易多了。
2.1 为什么L2正则化可以有效防止过拟合
我们考虑如下带L2正则化的损失函数:
\[C =C_0+\alpha \sum_w w^2\]画出他们在二维平面上的图形:
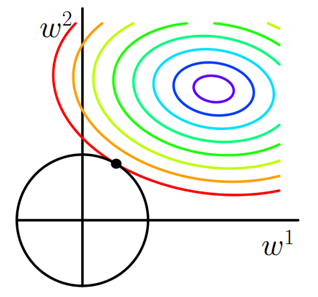
二维平面下L2正则化的函数图形是个圆(绝对值的平方和,是个圆),与方形相比,被磨去了棱角。因此$C_0$与L2相交时使得$w^1,w^2$等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因,因为不太可能出现多数$w$都为0的情况。
模型参数和过拟合之间的关系:
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
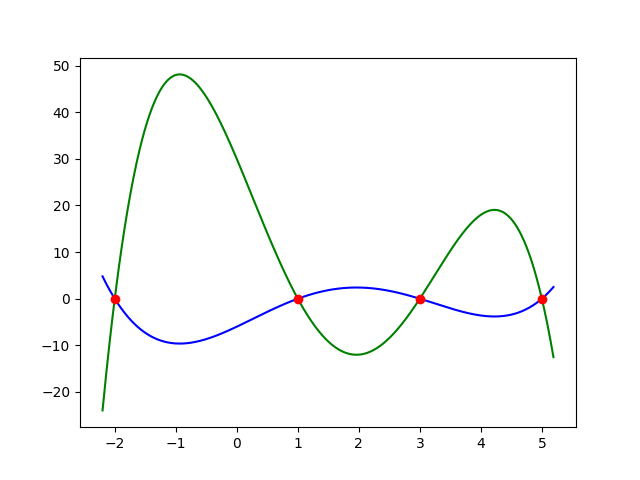
其中绿色曲线的函数为:
\[h_1(x)=-x^4+7x^3-5x^2-31x+30\]红色曲线的函数为:
\[h_2(x)=\frac{x^4}{5}-\frac{7x^3}{5}+x^2+\frac{31x}{5}-6\]比较这两个曲线我们可以发现,较小的权重系数可以有效防止过拟合。
L2正则可以获得更小的模型参数:
考虑下式:
\[C = C_0+\frac{\lambda}{2m}\sum_w w^2\]其中$m$为样本数。
推导过程:
\[\frac{\partial C}{\partial w}=\frac{\partial C_0}{\partial w}+\frac{\lambda}{m}w\] \[\frac{\partial C}{\partial b}=\frac{\partial C_0}{\partial b}\]可以发现L2正则化项对$b$的更新没有影响,但是对$w$的更新有影响:
\[\begin{aligned} w &\rightarrow w-\eta\frac{\partial C_0}{\partial w}-\eta\frac{\lambda}{m}w \\ &=(1-\frac{\eta \lambda}{m})w-\eta\frac{\partial C_0}{\partial w} \end{aligned}\]在不使用L2正则化时,求导结果中$w$前系数为1,现在系数为$1-\frac{\eta \lambda}{m}$,它的效果是减小$w$,从而防止过拟合。
三、L2正则,weight decay在SGD,Adam中的理解
首先我们应该了解到L2正则与weight decay的区别
L2正则:通过添加正则项在损失函数中: $$ C=C_0+\frac{\lambda}{2m}w^2 $$ weight decay:通过添加正则导数项在参数更新过程中: $$ w \rightarrow w-\eta\frac{\partial C_0}{\partial w}-\eta\frac{\lambda}{m}w $$在标准SGD的情况下,通过对衰减系数做变换,可以将L2正则和Weight Decay看做一样。但是在Adam这种自适应学习率算法中两者并不等价。
使用Adam优化带L2正则的损失并不有效。如果引入L2正则项,在计算梯度的时候会加上对正则项求梯度的结果。那么如果本身比较大的一些权重对应的梯度也会比较大,由于Adam计算步骤中减去项会有除以梯度平方的累积,使得减去项偏小。按常理说,越大的权重应该惩罚越大,但是在Adam并不是这样。而权重衰减对所有的权重都是采用相同的系数进行更新,越大的权重显然惩罚越大。在常见的深度学习库中只提供了L2正则,并没有提供权重衰减的实现。这可能就是导致Adam跑出来的很多效果相对SGD with Momentum偏差的一个原因。
下图中的绿色部分就是在Adam中正确引入Weight Decay的方式,称作AdamW。

Reference
(1) https://www.cnblogs.com/alexanderkun/p/6922428.html
(2) https://blog.csdn.net/jinping_shi/article/details/52433975
(3) https://zhuanlan.zhihu.com/p/40814046


如果你觉得本文对你有帮助,不妨请我喝杯咖啡